dRender - a Distributed, Fault Tolerant Rendering System

Sample Blender Scene Rendered Using dRender
dRender
I was taking this course, Building Reliable Distributed Systems in my last semester of grad school at Carnegie Mellon, and as the name of the course suggests, we were asked to build a reliable distributed system. Having worked in the animation industry (DreamWorks Animation) before joining CMU, I wanted to build something that combined my love for computer graphics and distributed systems. And hence came, dRender.
Simply put, dRender uses the resources in the cloud to render out a Computer Graphics (CG) scene for you. Most of the big animation/visual effects studios leverage big render farms to render their complicated scenes. However, artists at home who might be limited by the capacity of their hardware might not be able to work as efficiently. dRender lets you leverage machines in the cloud to take a scene with lot of frames to render, distribute the workload, render the scenes for you, and download it back to your machine. The cost is minimal because you’re only charged for the amount of time you used the resources.
What did I use?
Architecture
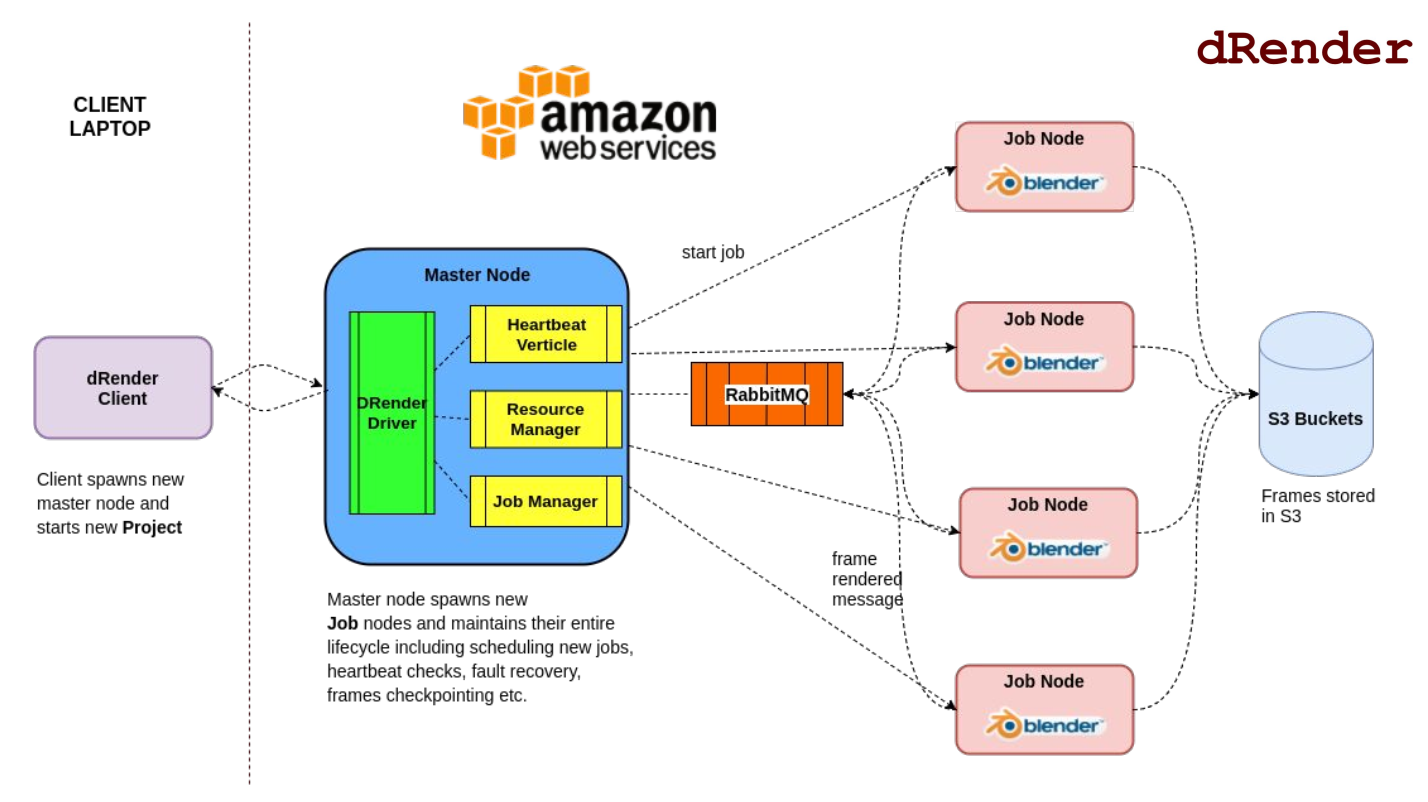
dRender has 3 primary components:
1. Client
Client is responsible for maintaining user projects - spinning up the projects, spinning up/shutting down Master Node, giving status of client projects etc.
2. Master Node
Master Node is responsible for co-ordinating the entire lifecycle of a project doing things like - scheduling, heartbeat checks, fault recovery, checkpointing etc.
3. Job Node
Job Node (or “worker” node) is responsible for performing the render task assigned to it.
Overall Characteristics
1) Client Node is reliable - A client node may be used to spawn multiple projects and it should be able to handle those independently.
2) Fault Tolerant - any Job Node can fail, the Master Node should be able to detect and reschedule jobs on some other machine.
3) All parameters are configurable. For example - Frames per machine, type of machine, rendering parameters, video output format etc.
Client
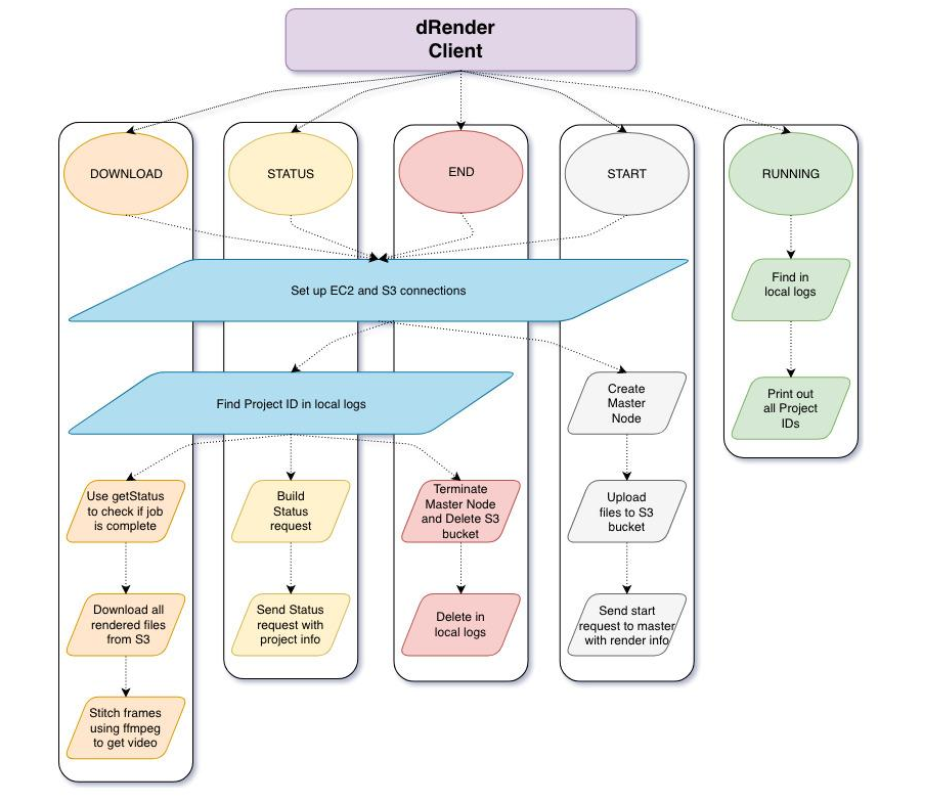
This is the user interface. A user of dRender will only interact with this subsystem. Summary of things it does -
- Sets up the Master Node and the S3 bucket for file handling.
- A user can interact using 5 possible commands
STARTSTATUSDOWNLOADRUNNINGEND
- Each command requires its own set of arguments, details of which are there in the Github repository.
Master Node
Master Node is responsible for orchestrating the entire flow of spawning new machines, scheduling jobs, and collecting results. Master Node is a RESTful service developed using the Vertx framework - which is an event-driven, non-blocking application framework. This enables Master Node to behave asynchronously without having to maintain a large number of threads.
Summary of the components within Master Node and the things they do -
DRenderDriver
This is the main co-ordinator within Master node. It initializes project parameters, prepares Jobs to schedule, spawns new machines based on number of Jobs, starts the jobs on machines, schedule heartbeat checks, schedule Job completion checks etc.
Heartbeat Verticle
This component is responsible for periodically doing a “health check” on the assigned peers every 15 seconds. If it does not receive a response from the machine, it decides to restart the machine or inform DRenderDriver about this for it to take appropriate action.
RabbitMQ
All the messaging between the Master Node and Job Nodes take place using messaging queues, in this case, using RabbitMQ. The Job Nodes listen on those queues for new Job’s, and start rendering as soon as a Job is available.
Job Manager
Responsible for co-ordinating with Job Nodes. It can start, stop, or check for status of a Job and communicate with DRenderDriver.
Job Node
As its already clear by now, Job Node is responsible for rendering an individual frame (or a subset of frames) within a scene. It receives all the information like scene location, frame range to render, where to store the frames etc. As it renders each frame, it stores the frames in AWS S3 storage, and communicates back with Master Node using message queues (RabbitMQ).
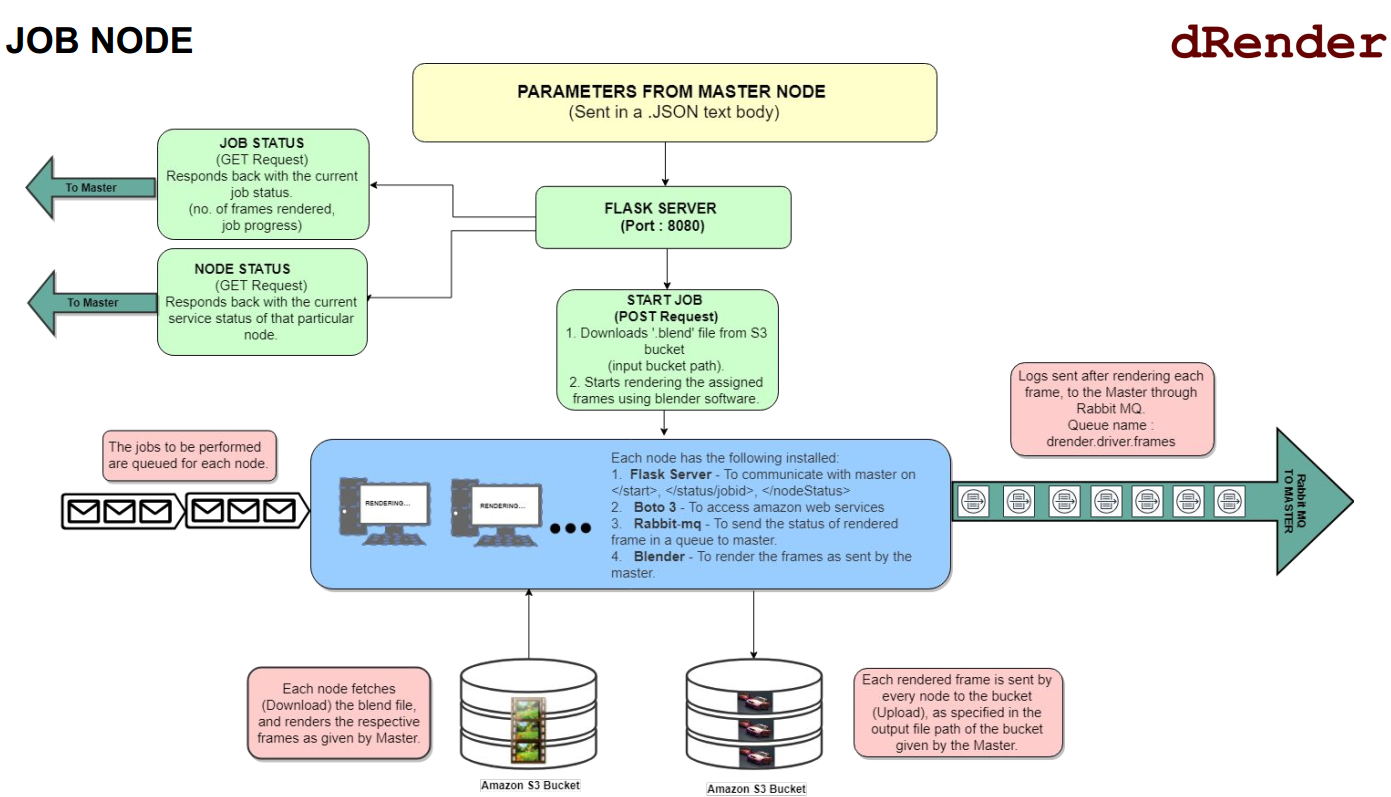
Job Node Flow
Fault Tolerance
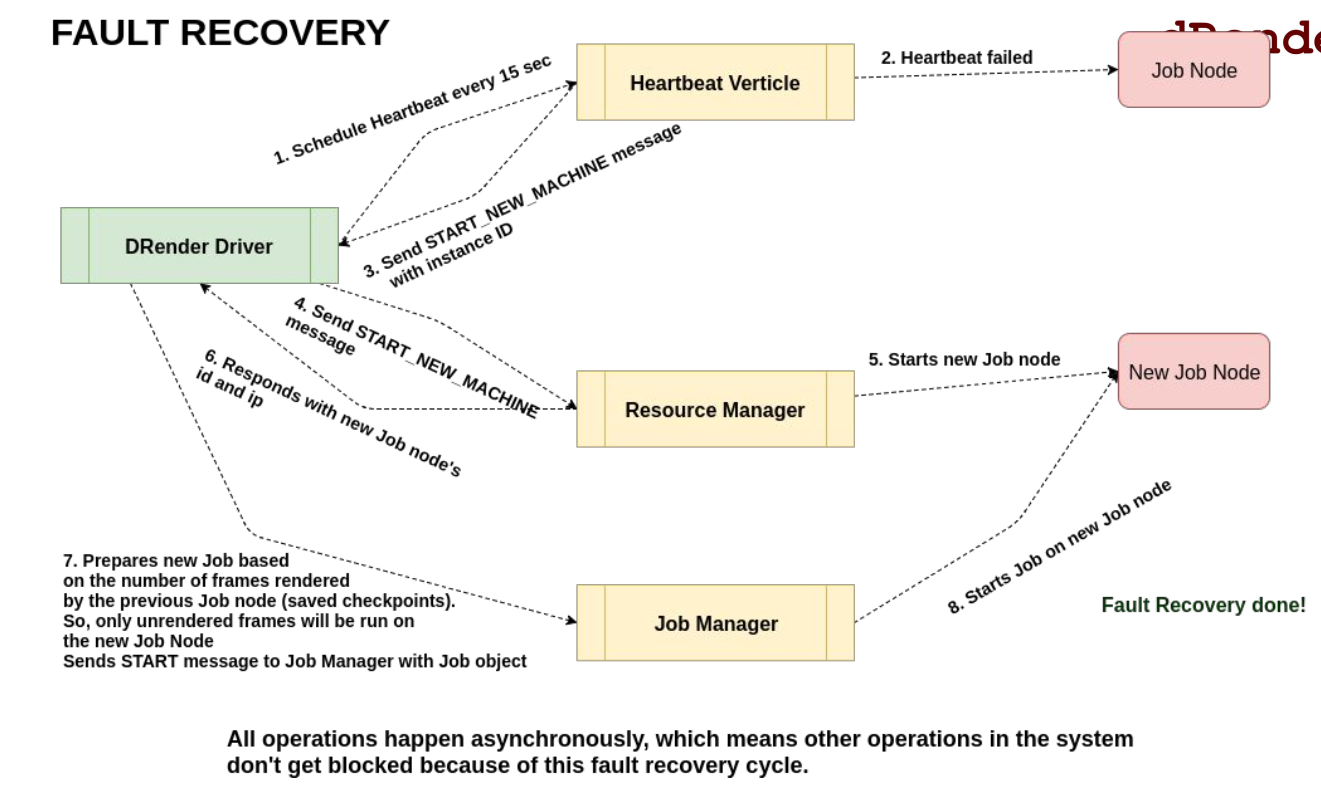
As I had briefly mentioned above, this system was designed to be fault tolerant, meaning it had to be resilient against Job Nodes failing randomly. We were using AWS EC2 Spot Instances for spawning Job Nodes. Spot Instances are very cheap because they let you use the unused capacity in the AWS cloud, but that also means that AWS could reclaim it at any time.
To protect against that, and against random failures in the machines, the HeartBeat Verticle in Master Node regularly checkpointed the Job Nodes, and if it detected the nodes failing beyond a certain threshold, it rescheduled all its Jobs on a new node. Here’s a diagram describing the process in further detail.
Conclusion
This was quite a fun project to work on as we got to touch on many aspects of the Reliable Distributed Systems concepts that we were learning in our course. It was also quite fun to be able to see those frames getting rendered one by one across machines and then stiching them together.
There was a lot to learn as well. It made us dive deep into some of the nitty gritties of the AWS EC2 ecosystem, and the Identity Access Management (IAM) system that was necessary to be able to securely do the operations without explicitly passing keys around.
This project was of course, a prototype of what the actual system could be. Nevertheless, this gave me a lot of insight into how complex the CG world is, and maybe someday I’ll get myself to develop this into a full blown piece of software :)