High Performant, Scalable Twitter Analytics Web-Service in the Cloud

Twitter generates enormous amounts of data per day, and that data can be used to build APIs that make the platform even better. As the title suggests, we designed, developed, and deployed a web service that was high performant, reliable, and scalable, all done within the budget allocated for our team. We were given over 1 Terabyte of raw tweets for our consumption. We implemented 4 queries (APIs) for our web service which used this data in a processed form. This was a massive project which spanned over a month.
What did I use?
- Java
- SpringBoot
- Hibernate
- Undertow
- MapReduce
- Maven
- MySQL
- HBase
- Terraform
- Google Cloud Platform (GCP)
- Amazon Web Services (AWS)
Key Facts
- Number of queries (APIs) - 4
- Budget - $150 (over 3 phases)
- Size of dataset - over 1 Terabyte (TB) raw tweet data
- Throughput achieved (round figures) -
Query 1 - 31000 rps
Query 2 - 13000 rps
Query 3 - 5000 rps
Query 4 - 4500 rps
Implementation
Since the project was massive and there were lot of components involved, I will be superficially going over the queries we implemented. However, I can’t dive into the exact specifics of the implementation (as it violates academic integrity, and also it’s a lot to type :)). The key objectives of the project were:
- Build a performant and reliable web service on the cloud within a specified budget by combining the skills developed in the Cloud Computing course.
- Design, develop, deploy and optimize functional web-servers that could handle a high load (~ tens of thousands of requests per second).
- Implement Extract, Transform and Load (ETL) on a large data set (~ 1 TB) and load the data into MySQL and HBase systems.
- Design schema as well as configure and optimize MySQL and HBase databases to deal with scale and improve throughput.
- Explore methods to identify the potential bottlenecks in a cloud-based web service and methods to improve system performance.
- Develop fault-tolerant, scalable web-servers to respond to a live load.
Query 1: Heartbeat and QR Code
Throughput Achieved: 31000 rps
This was a ramp-up task which made sure that the team had a working web service. This query didn’t require to design and deploy a database. It was used as a heartbeat mechanism to check whether the service was running. In query 1, we were required to encode plain texts into simplified QR codes and also decode the text messages from given QR codes.
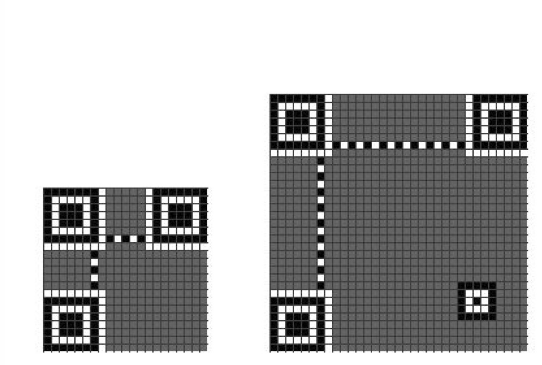
The actual QR Code has a lot of versions of different sizes, of which we had to implement 2 of the specified sizes - 21x21 and 25x25
Sample requests:
Request:
GET /q1?type=encode&data=CC%20Team
Response:
"0xfe33fc140xd06ea2bb0x7595dbac0xaec121070xfaafe00c0xb32450xce10b7980x490419c0x2340001c0x47f844300x5315bac90x25d18c2e0xa60505140x1fd8a2"
Request:
GET /q1?type=decode&data=0x294acd760xfe823fc00x82bc20fd0xba60aeac0xbaf12ee20xbad82eeb0x82c420d00xfeaabfd70x37801e0x807624430x80146b50x8036a0750xed018e040x8032a0520xdd0106ea0x809020690x9c0116f80x1f90204a0x8db00720x1a80bfff0x688020920x1fb2aeb20x2a82ea20x4802e9e0x30a020bd0x13433fea0xf879a0250xe281253c0x386ba9e90xcb8ac96a0x3bb6b9480x3cb69f31
Response:
"CC Team is awesome!"
Query 2: Hashtag Recommendation System
Throughput Achieved: 13000 rps
This query predicted the hashtags for a new tweet by a particular user using the over 1 TB raw tweet data. We were given the keywords in a new tweet, the user information and the number of hashtags required, and our system needed to predict the hashtags that were best suited for the tweet by that user using the twitter dataset.
The request of Q2 provided a few keywords (keywords being present in a new tweet) , a user id and a number n, for which the system needed to respond with:
The top n hashtags which were present with the given keywords (using an elaborate ranking algorithm).
Sample requests:
Request:
GET /q2?keywords=<a_string_of_comma_’,’_seperated_keywords>&n=a_number&user_id=a_number
Response:
TEAMID,TEAM_AWS_ACCOUNT_ID\n
#hashtag1,#hashtag2,........#hashtagn\n
Query 3: Range Query and Topic Words Extraction
Throughput Achieved: 5000 rps
This query extracted the tweets and topic words based on the given input parameters. The query took in requests which had the time range, uid range, the maximum number of topic words (n1), and the maximum number of tweets that should be returned (n2), and:
- Found All the tweets posted by a user within the uid range AND within the given time range.
- Calculated the
topic score, which was a modified version of TF-IDF (described later) to extract the topic words. - Sorted and returned at most
n1topic words and returned them along with at mostn2sorted tweets (sorted by their impact scores), which contained at least one of thosen1topic words.
The service implementation also had to handle invalid/corner cases, and had to be secure enough to handle basic vulnerabilities like SQL injection. The impact scores and topic words were calculated using clearly defined algorithms.
Sample request:
Request:
GET /q3?uid_start=2317544238&uid_end=2319391795&time_start=1402126179&time_end=1484854251&n1=10&n2=8
Response:
TEAM_NAME,TEAM_AWS_ID
word1:score1\tword2:score2...\twordn1:scoren1
impactscore1\ttid1\ttext1
impactscore2\ttid2\ttext2
...
impactscoren2\ttidn2\ttextn2
This query also required us to censor the tweet texts having words among given words in ROT13 cipher. This was also handled as part of the ETL (Extract, Transform, and Load) process.
Query 4: Consistent Read/Write
Throughput Achieved: 4500 rps
In this query, we built a web service that supported READ, WRITE, SET, and DELETE operations on tweets. The fields of relevance from the tweet data were: tweetid, timestamp, userid, username, text, favorite_count, and retweet_count. This was a complex query to implement as we had a distributed database and we had to achieve an almost strong consitency model. Few bits of information about the query:
- Operations under the same
uuidneeded to be handled in the order of the corresponding value ofseq. That is, all operations with sequence numberssor higher needed to wait for the operation with the sequence numbers-1to finish. - However, operations with different value of uuid represented operations in different sequences, and they did not share the sequence numbers.
- The
WRITEoperations did not change the user who posted the tweet.
Sample requests:
READ
Request:
GET /q4?op=read&uid1=userid_1&uid2=userid_2&n=max_number_of_tweets&uuid=unique_id&seq=sequence_number
Response:
TEAMID,TEAM_AWS_ACCOUNT_ID\n
tid_1\ttimestamp_1\tuid_1\tusername_1\ttext_1\tfavorite_count_1\tretweet_count_1\n
...
tid_n\ttimestamp_n\tuid_n\tusername_n\ttext_n\tfavorite_count_n\tretweet_count_n\n
WRITE
Request:
GET /q4?op=write&payload=json_string&uuid=unique_id&seq=sequence_number
Response:
TEAMID,TEAM_AWS_ACCOUNT_ID\n
success\n
SET
Request:
GET /q4?op=set&field=field_to_set&tid=tweet_id&payload=string&uuid=unique_id&seq=sequence_number
Response:
TEAMID,TEAM_AWS_ACCOUNT_ID\n
success\n
DELETE
Request:
GET /q4?op=delete&tid=tweet_id&uuid=unique_id&seq=sequence_number
Response:
TEAMID,TEAM_AWS_ACCOUNT_ID\n
success\n
Since it was required to achieve good consitency while maintaining the high throughput, we designed algorithm where a Coordinator was responsible for allocating/parallelizing requests to the services. We also had to write Connection Handlers that could keep delegating live connections to the requests, and closing it back once used, to avoid hogging the database with too many connections.
ETL Process
Each of the queries (except Query 1) required us to extract and transform the 1TB of raw data into a form which could then be consumed by the MySQL database. We decided to perform the entire extraction and transformation process in Google Cloud Platform. We wrote Mappers and Reducers to filter out bad/irrelevant data and converted them as required by each query. We run the jobs in clusters having 8 memory-optimized machines (1 master and 7 slaves). The process took around 2.5 hours to complete.
After that, we wrote scripts to efficiently load the data into the database, while maintaining the encoding information (there were several languages other than English too). This process took another 2-3 hours (varied per query). The entire ETL process took around 6-7 hours! So, we had to be plan everything out on paper before deciding to change anything!
Performance Optimizations
To achieve a good throughput with the constraints on budget and resources, we had to explore several optimization techniques. It started with choosing the right framework for the project. In our case, we chose SpringBoot with Undertow server. We came to this decision as its a popular industry choice (compared benchmarks) and we also did some benchmarking of our own.
Second, we had to improve the performance of the database where a major bottleneck lied. We explored different schemas to store the data and also to reduce the amount of data stored in the database. We utilized other techniques like indexing, database tuning and sharding to speedup or performance.
Third, we had to have efficient programming. There was a good chunk of calculations which happened in code as well after fetching the data. So, we tried to utilize multi-threading programming to parallelize the computations as much as possible. But, we also had to be careful and control the use of multi-threading without it becoming a bottleneck.
Deployment
We had a budget constraint of the maximum cost/hour that could be incurred. Keeping budget in mind, we used several m4.large instances to deploy the database and services. To balance and distribute the load, we used the Elastic Load Balancer (ELB) service provided by AWS. We also had to continuously monitor the load among all instances, and be ready for unforeseen circumstances. We used the tmux to split the terminals and simultaneously configure and monitor the instances, as shown.
Conclusion
This was a very challenging and exciting project. We were involved in every part of the process, from designing the solution, to extracting the data, to implementing the services, and deploying and monitoring them. It gave us really good hands-on experience with different aspects of the pipeline. There were many challenges along the way, but we were able to successfully steer through the hurdles one at a time.